 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWenetSpeech-Wu: Datasets, Benchmarks, and Models for a Unified Chinese Wu Dialect Speech Processing Ecosystem
Jan 16, 2026Speech processing for low-resource dialects remains a fundamental challenge in developing inclusive and robust speech technologies. Despite its linguistic significance and large speaker population, the Wu dialect of Chinese has long been hindered by the lack of large-scale speech data, standardized evaluation benchmarks, and publicly available models. In this work, we present WenetSpeech-Wu, the first large-scale, multi-dimensionally annotated open-source speech corpus for the Wu dialect, comprising approximately 8,000 hours of diverse speech data. Building upon this dataset, we introduce WenetSpeech-Wu-Bench, the first standardized and publicly accessible benchmark for systematic evaluation of Wu dialect speech processing, covering automatic speech recognition (ASR), Wu-to-Mandarin translation, speaker attribute prediction, speech emotion recognition, text-to-speech (TTS) synthesis, and instruction-following TTS (instruct TTS). Furthermore, we release a suite of strong open-source models trained on WenetSpeech-Wu, establishing competitive performance across multiple tasks and empirically validating the effectiveness of the proposed dataset. Together, these contributions lay the foundation for a comprehensive Wu dialect speech processing ecosystem, and we open-source proposed datasets, benchmarks, and models to support future research on dialectal speech intelligence.
Crystal Generation using the Fully Differentiable Pipeline and Latent Space Optimization
Jan 08, 2026We present a materials generation framework that couples a symmetry-conditioned variational autoencoder (CVAE) with a differentiable SO(3) power spectrum objective to steer candidates toward a specified local environment under the crystallographic constraints. In particular, we implement a fully differentiable pipeline that performs batch-wise optimization on both direct and latent crystallographic representations. Using the GPU acceleration, the implementation achieves about fivefold speed compared to our previous CPU workflow, while yielding comparable outcomes. In addition, we introduce the optimization strategy that alternatively performs optimization on the direct and latent crystal representations. This dual-level relaxation approach can effectively overcome local barrier defined by different objective gradients, thus increasing the success rate of generating complex structures satisfying the targe local environments. This framework can be extended to systems consisting of multi-components and multi-environments, providing a scalable route to generate material structures with the target local environment.
Lifelong Domain Adaptive 3D Human Pose Estimation
Dec 29, 20253D Human Pose Estimation (3D HPE) is vital in various applications, from person re-identification and action recognition to virtual reality. However, the reliance on annotated 3D data collected in controlled environments poses challenges for generalization to diverse in-the-wild scenarios. Existing domain adaptation (DA) paradigms like general DA and source-free DA for 3D HPE overlook the issues of non-stationary target pose datasets. To address these challenges, we propose a novel task named lifelong domain adaptive 3D HPE. To our knowledge, we are the first to introduce the lifelong domain adaptation to the 3D HPE task. In this lifelong DA setting, the pose estimator is pretrained on the source domain and subsequently adapted to distinct target domains. Moreover, during adaptation to the current target domain, the pose estimator cannot access the source and all the previous target domains. The lifelong DA for 3D HPE involves overcoming challenges in adapting to current domain poses and preserving knowledge from previous domains, particularly combating catastrophic forgetting. We present an innovative Generative Adversarial Network (GAN) framework, which incorporates 3D pose generators, a 2D pose discriminator, and a 3D pose estimator. This framework effectively mitigates domain shifts and aligns original and augmented poses. Moreover, we construct a novel 3D pose generator paradigm, integrating pose-aware, temporal-aware, and domain-aware knowledge to enhance the current domain's adaptation and alleviate catastrophic forgetting on previous domains. Our method demonstrates superior performance through extensive experiments on diverse domain adaptive 3D HPE datasets.
The TEA-ASLP System for Multilingual Conversational Speech Recognition and Speech Diarization in MLC-SLM 2025 Challenge
Jul 24, 2025This paper presents the TEA-ASLP's system submitted to the MLC-SLM 2025 Challenge, addressing multilingual conversational automatic speech recognition (ASR) in Task I and speech diarization ASR in Task II. For Task I, we enhance Ideal-LLM model by integrating known language identification and a multilingual MOE LoRA structure, along with using CTC-predicted tokens as prompts to improve autoregressive generation. The model is trained on approximately 180k hours of multilingual ASR data. In Task II, we replace the baseline English-Chinese speaker diarization model with a more suitable English-only version. Our approach achieves a 30.8% reduction in word error rate (WER) compared to the baseline speech language model, resulting in a final WER of 9.60% in Task I and a time-constrained minimum-permutation WER of 17.49% in Task II, earning first and second place in the respective challenge tasks.
AI-Assisted Rapid Crystal Structure Generation Towards a Target Local Environment
Jun 09, 2025



In the field of material design, traditional crystal structure prediction approaches require extensive structural sampling through computationally expensive energy minimization methods using either force fields or quantum mechanical simulations. While emerging artificial intelligence (AI) generative models have shown great promise in generating realistic crystal structures more rapidly, most existing models fail to account for the unique symmetries and periodicity of crystalline materials, and they are limited to handling structures with only a few tens of atoms per unit cell. Here, we present a symmetry-informed AI generative approach called Local Environment Geometry-Oriented Crystal Generator (LEGO-xtal) that overcomes these limitations. Our method generates initial structures using AI models trained on an augmented small dataset, and then optimizes them using machine learning structure descriptors rather than traditional energy-based optimization. We demonstrate the effectiveness of LEGO-xtal by expanding from 25 known low-energy sp2 carbon allotropes to over 1,700, all within 0.5 eV/atom of the ground-state energy of graphite. This framework offers a generalizable strategy for the targeted design of materials with modular building blocks, such as metal-organic frameworks and next-generation battery materials.
Delayed-KD: Delayed Knowledge Distillation based CTC for Low-Latency Streaming ASR
May 28, 2025



CTC-based streaming ASR has gained significant attention in real-world applications but faces two main challenges: accuracy degradation in small chunks and token emission latency. To mitigate these challenges, we propose Delayed-KD, which applies delayed knowledge distillation on CTC posterior probabilities from a non-streaming to a streaming model. Specifically, with a tiny chunk size, we introduce a Temporal Alignment Buffer (TAB) that defines a relative delay range compared to the non-streaming teacher model to align CTC outputs and mitigate non-blank token mismatches. Additionally, TAB enables fine-grained control over token emission delay. Experiments on 178-hour AISHELL-1 and 10,000-hour WenetSpeech Mandarin datasets show consistent superiority of Delayed-KD. Impressively, Delayed-KD at 40 ms latency achieves a lower character error rate (CER) of 5.42% on AISHELL-1, comparable to the competitive U2++ model running at 320 ms latency.
Selective Invocation for Multilingual ASR: A Cost-effective Approach Adapting to Speech Recognition Difficulty
May 22, 2025Although multilingual automatic speech recognition (ASR) systems have significantly advanced, enabling a single model to handle multiple languages, inherent linguistic differences and data imbalances challenge SOTA performance across all languages. While language identification (LID) models can route speech to the appropriate ASR model, they incur high costs from invoking SOTA commercial models and suffer from inaccuracies due to misclassification. To overcome these, we propose SIMA, a selective invocation for multilingual ASR that adapts to the difficulty level of the input speech. Built on a spoken large language model (SLLM), SIMA evaluates whether the input is simple enough for direct transcription or requires the invocation of a SOTA ASR model. Our approach reduces word error rates by 18.7% compared to the SLLM and halves invocation costs compared to LID-based methods. Tests on three datasets show that SIMA is a scalable, cost-effective solution for multilingual ASR applications.
Enhancing Non-Core Language Instruction-Following in Speech LLMs via Semi-Implicit Cross-Lingual CoT Reasoning
Apr 29, 2025



Large language models have been extended to the speech domain, leading to the development of speech large language models (SLLMs). While existing SLLMs demonstrate strong performance in speech instruction-following for core languages (e.g., English), they often struggle with non-core languages due to the scarcity of paired speech-text data and limited multilingual semantic reasoning capabilities. To address this, we propose the semi-implicit Cross-lingual Speech Chain-of-Thought (XS-CoT) framework, which integrates speech-to-text translation into the reasoning process of SLLMs. The XS-CoT generates four types of tokens: instruction and response tokens in both core and non-core languages, enabling cross-lingual transfer of reasoning capabilities. To mitigate inference latency in generating target non-core response tokens, we incorporate a semi-implicit CoT scheme into XS-CoT, which progressively compresses the first three types of intermediate reasoning tokens while retaining global reasoning logic during training. By leveraging the robust reasoning capabilities of the core language, XS-CoT improves responses for non-core languages by up to 45\% in GPT-4 score when compared to direct supervised fine-tuning on two representative SLLMs, Qwen2-Audio and SALMONN. Moreover, the semi-implicit XS-CoT reduces token delay by more than 50\% with a slight drop in GPT-4 scores. Importantly, XS-CoT requires only a small amount of high-quality training data for non-core languages by leveraging the reasoning capabilities of core languages. To support training, we also develop a data pipeline and open-source speech instruction-following datasets in Japanese, German, and French.
DanceMosaic: High-Fidelity Dance Generation with Multimodal Editability
Apr 06, 2025Recent advances in dance generation have enabled automatic synthesis of 3D dance motions. However, existing methods still struggle to produce high-fidelity dance sequences that simultaneously deliver exceptional realism, precise dance-music synchronization, high motion diversity, and physical plausibility. Moreover, existing methods lack the flexibility to edit dance sequences according to diverse guidance signals, such as musical prompts, pose constraints, action labels, and genre descriptions, significantly restricting their creative utility and adaptability. Unlike the existing approaches, DanceMosaic enables fast and high-fidelity dance generation, while allowing multimodal motion editing. Specifically, we propose a multimodal masked motion model that fuses the text-to-motion model with music and pose adapters to learn probabilistic mapping from diverse guidance signals to high-quality dance motion sequences via progressive generative masking training. To further enhance the motion generation quality, we propose multimodal classifier-free guidance and inference-time optimization mechanism that further enforce the alignment between the generated motions and the multimodal guidance. Extensive experiments demonstrate that our method establishes a new state-of-the-art performance in dance generation, significantly advancing the quality and editability achieved by existing approaches.
HOIGPT: Learning Long Sequence Hand-Object Interaction with Language Models
Mar 24, 2025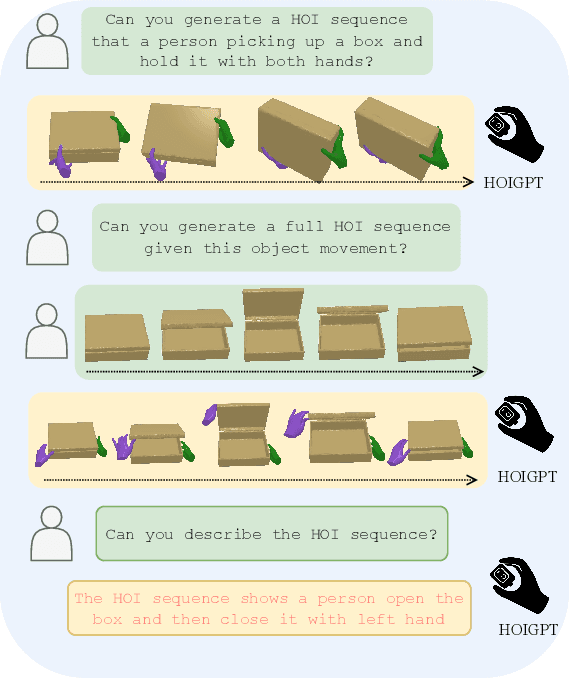

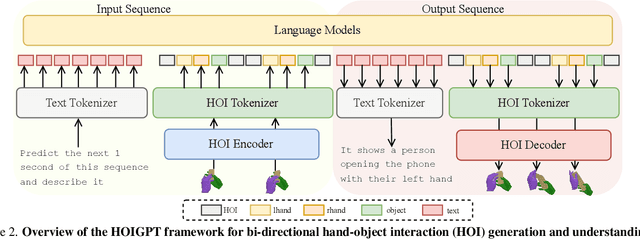

We introduce HOIGPT, a token-based generative method that unifies 3D hand-object interactions (HOI) perception and generation, offering the first comprehensive solution for captioning and generating high-quality 3D HOI sequences from a diverse range of conditional signals (\eg text, objects, partial sequences). At its core, HOIGPT utilizes a large language model to predict the bidrectional transformation between HOI sequences and natural language descriptions. Given text inputs, HOIGPT generates a sequence of hand and object meshes; given (partial) HOI sequences, HOIGPT generates text descriptions and completes the sequences. To facilitate HOI understanding with a large language model, this paper introduces two key innovations: (1) a novel physically grounded HOI tokenizer, the hand-object decomposed VQ-VAE, for discretizing HOI sequences, and (2) a motion-aware language model trained to process and generate both text and HOI tokens. Extensive experiments demonstrate that HOIGPT sets new state-of-the-art performance on both text generation (+2.01% R Precision) and HOI generation (-2.56 FID) across multiple tasks and benchmarks.